Code is the best documentation place at the end, and despites the fact that reading it is time consuming and hard to understand, sometimes it could make you happier.
This post is about the unrelated things I found (for now) in docker code.
The meaning of life
Given the name of the blog, this one is not unnoticed to my eyes.
I enjoyed this wink, I mean, the whole file. It is worth to read it all, since all the names are quoted and this quick reference could wake up some interest about someone.
begin:name:=fmt.Sprintf("%s_%s",left[rand.Intn(len(left))],right[rand.Intn(len(right))])ifname=="boring_wozniak"/* Steve Wozniak is not boring */{gotobegin}
I have to say I agree.
At least they are not as hard as the ones in linux code.
Namespaces are used to provide a process or a group of processes with the idea of being the only process or group of processes in the system.
They are a way to detach processes from a specific kernel layer assigning them to a new one. Or in other words, they are indirections layers for global resources.
Lets imagine this as an extension to classical chroot() syscall. When setting a new root calling chroot, kernel was isolating new branch from existing one, and thus creating a new namespace for the process.
Namespaces now provide the basis for a complete lightweight virtualization system, in the form of containers.
Currently, linux support following namespaces
NameSpace
from Kernel
Descrition
UTS
2.6.19
domain and hostname
IPC
2.6.19
queues, semaphores, and shared memmory
PID
2.6.19
pid
NS
2.4.19
Filesystems
NET
2.4.24
IP, routes, network devices…
USER
3.8
Uid, Guid,…
I let individual namespaces explanations as simple as this, or in other words, for another day.
Namespaces API
In Linux kernel there are not distinction between process and threads implementions, threads are just light weight processes. Threads are also created by calling clone() but with different arguments (CLONE_VM mainly). From the kernel point of view, a process/thread is a task.
Namespaces can be nested. Limit for nesting namespaces is 32.
Namespaces can be created or modified by clone(), unshare() and setns() system calls. All of them are not POSIX system calls, so only available in linux.
clone() system call is more specific than fork() or vfork() system calls. They are alike, because they are implemented by calling do_fork() function with different flags and args.
copy_process() function in do_fork() calls copy_namespaces(). In case any namespace flags present, it just uses parent namespaces. (fork(), vfork() behavior)
Flags like CLONE_NEW* flags have same effect as they have in clone(). All others ones that unshare() accepts has reverse effect. Since they were copied in above create_new_namespaces example.
When a task ends, all namespaces they belong to that does not have any other process attached are cleaned. This means, mounts unmounted, network interfaced destroyed, etc.
fd argument specifies the namespace to join. It is translated to a nscommon struct calling get_proc_ns(file_inode(file)). We will cover fds in next point.
Per process namespaces can be found under /proc/$pid/ns.
12345678
$ ls -l /proc/$$/ns
total 0
lrwxrwxrwx 1 ubuntu ubuntu 0 Jan 5 21:12 ipc -> ipc:[4026531839]lrwxrwxrwx 1 ubuntu ubuntu 0 Jan 5 21:12 mnt -> mnt:[4026531840]lrwxrwxrwx 1 ubuntu ubuntu 0 Jan 5 21:12 net -> net:[4026531962]lrwxrwxrwx 1 ubuntu ubuntu 0 Jan 5 21:12 pid -> pid:[4026531836]lrwxrwxrwx 1 ubuntu ubuntu 0 Jan 5 21:12 user -> user:[4026531837]lrwxrwxrwx 1 ubuntu ubuntu 0 Jan 5 21:12 uts -> uts:[4026531838]
Each process namespace has an inode number, that corresponds with a namespace struct. If two tasks share same number, they belongs to same namespace. Inode for ns files in namespaces is not the same as stat -c %i shows. They are sym links.
For namespaces, like sockets or pipes inode number is shown in form type:[inode].
123456789101112131415
# for pid in 643 23681 32178 ; do readlink /proc/$pid/ns/mnt ; donemnt:[4026531840]mnt:[4026532430]mnt:[4026532430]# for pid in 643 23681 32178 ; do md5sum /proc/$pid/mounts ; done8dddf7d919672a56849bb487840b94e0 /proc/643/mounts
70159c37e8c8f16c61ceaa047ad9528a /proc/23681/mounts
70159c37e8c8f16c61ceaa047ad9528a /proc/32178/mounts
# unshare -m /bin/bash # readlink /proc/$$/ns/mntmnt:[4026532493]# for pid in 643 23681 32178; do stat -c %i /proc/$pid/ns/mnt ; done1308868
1308731
1308686
Proc namespaces files are implemented through proc_ns_operations struct.
There are availabe two commands that correspond to each system call (like most of the shell commands that are just called like any system call). unshare for unshare() and nsenter for setns().
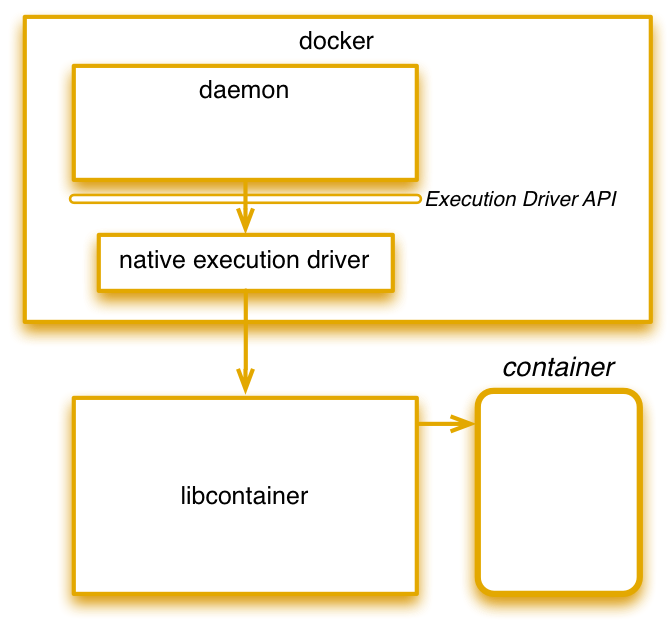
Libcontainer is now the default docker execution environment. It is driver (named native) and a library.
In other words, it is a replacement (since version 0.9) for formerly LXC execution environment (that can be easily brought back using -e switch).
This library is developed by docker.io, written in go and C/C++, in order to support a wider range of isolation technologies. It also can be used in python through python bindings.
It is meant to be a cross-system abstraction layer being an attempt to standarize the way apps are packed up, delivered, and run in isolation.
Libcontainer as a stand alone project, makes possible to other game players adopting it. Google, parallels (openvz), redhat, ubuntu (lxc) are also contributing to this project.
This way, container features available in linux kernel API are provided as a unique library in a consistent way. LibContainer addresses the problem of having an unique kernel API and several implementations. (call them, LXC, libvirt, lmctfy, …)
Libcontainer enables containers to work with Linux namespaces, control groups, capabilities, AppArmor, security profiles, network interfaces and firewalling rules in a consistent and predictable way.
Currently, docker can support these kernel features out-of-the-box, since it no longer depends on LXC.
It introduces a new container specification as we can see here
It includes namespaces, standard filesystem setup, a default Linux capability set, and information about resource reservations. It also has information about any populated environment settings for the processes running inside a container.
Let`s see a little example of how it was replaced on docker code.
nsinit and nsenter are the user-land tools that now are needed in order to replace lxc-* user-land tools.
nsinit is part of libcontainer package and it is meant to load a config json file. It replaces lxc-start.
nsenter replaces lxc-attach and it is not part of libcontainer package, but it is part of util-linuxpackage.
When formerly we ran docker run ..., (by default) it called lxc-start to run the container.
func(d*driver)Run(c*execdriver.Command,pipes*execdriver.Pipes,startCallbackexecdriver.StartCallback)(execdriver.ExitStatus,error){// take the Command and populate the libcontainer.Config from itcontainer,err:=d.createContainer(c)
Other systems, like FreeBSD, implements ‘containers’ using Jails. It is an older concept, and some people note that it could not be as sofisticated as linux one is.
Here is as an example of an execution driver in development for FreeBSD Jails. Well, it is an execution driver for FreeBSD, therefore not using libcontainer.
Unfortunately, FreeBSD (and others flavours) mention on docker & libcontainer are only for go language.
A full list of OS level virtualization implementations can be found on wikipedia.
Hubot is your company’s robot. Install him in your company to dramatically improve and reduce employee efficiency.
In other words, hubot is a chat bot crafted by github team that can run custom written scritps. This allow us to automatize any kind of tasks like merging branches, deploying releases, do monitoring queries, inform (it listen on a port), etc. It has a lot of adapters (where it reads from and writes to), even shell, so we can enjoy its company almost everywhere.
FROM dockerfile/nodejs
MAINTAINER Marvin
WORKDIR /root
RUN npm install -g yo generator-hubot
RUN useradd -ms /bin/bash marvin
ENV HOME /home/marvin
# variables needed by hubot scripts
ADD env-vars.sh /home/marvin/.profile
RUN chown marvin /home/marvin/.profile
USER marvin
WORDIR /home/marvin
RUN echo n | yo hubot --defaults
RUN npm install hubot-slack hubot-scripts githubot --save
# enable plugins
RUN echo [ \'github-merge.coffee\' ] > hubot-scripts.json
CMD ["/home/marvin/bin/hubot", "--name", "marvin"]
EXPOSE 8080
Build an image with docker build -t cname/hubot . or just use the commands for testing it. Nodejs setup instructions can be found on joyent’s nodejs repo
Let me introduce you to Marvin, my hubot instance, named like Hitchhicker’s guide to galaxy assistant robot.
12345678910111213141516171819
_____________________________
/ \
//\ | Extracting input for |
////\ _____ | self-replication process |
//////\ /_____\ \ /
======= |[^_/\_]| /----------------------------
| | _|___@@__|__
+===+/ /// \_\
| |_\ /// HUBOT/\\
|___/\// / \\
\ / +---+
\____/ | |
| //| +===+
\// |xx|
marvin> marvin: the rules
1. A robot may not injure a human being or, through inaction, allow a human being to come to harm.
2. A robot must obey any orders given to it by human beings, except where such orders would conflict with the First Law.
3. A robot must protect its own existence as long as such protection does not conflict with the First or Second Law.
Janky is a hithub project that implements CI on top Jenkins and Hubot. Chatops term is used to refer chat based deployments and monitoring.
Github integration
One of the things I found interesting using hubot for is easy merging and deploy process.
In this article I am just going to treat merging as an example, but concepts shown here could be easily used for integrating it with jenkins or any other tools.
We can find some git related scripts under scripts folder in hubot-scripts github project.
This time I have tested github-merge.coffee plugin. It uses githubot project for github API access.
We need to set some variables in order this to work. They are made available to hubot as environment variables, so you can set them on env-vars.sh script mentioned in Dockerfile.
Enabling a plugin is as easy as adding it to hubot-scripts.json or external-scripts.json.
1
['github-merge.coffee']
Once configured we can check if plugin was loaded sucessfuly and works properly.
12345678
marvin> marvin help
[...]
marvin merge project_name/<head> into <base> - merges the selected branches or SHA commits
[...]
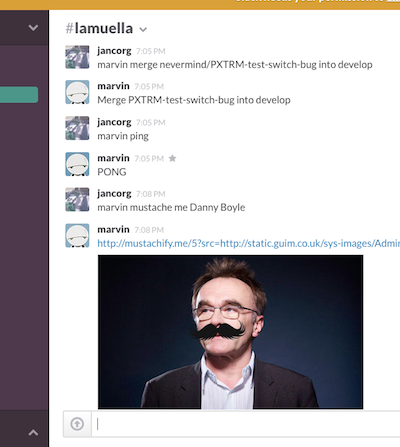
marvin> marvin merge nevermind/PXTRM-test-switch-bug into develop
marvin> Merge PXTRM-test-switch-bug into develop
marvin> marvin merge nevermind/PXTRM-merge-conflict-on-purpose into develop
marvin> [Fri Jan 02 2015 17:03:46 GMT+0000 (UTC)] ERROR 409 Merge conflict
It seems to work, and since it is using github merge API we are not messing any branch up.
Slack integration
I have chosen slack as default adapter since it is chat tool we are using at office. Hubots default one is campfire.
An organization, if you already don’t have one, needs to be created on slack. You can do it on sign up process.
When this is done, just configure integrations and look for hubot there. You will get a token and even you can set a custom avatar for you shinny bot.
Make this token availabe as environment varaible, and… that’s it.
Capabilities were created as an alternative to classical two level privilege system: root and user. They split a root acount into their privileges. This way, linux kernel allows a process to perform certain root tipical tasks without giving a process full root privileges.
A process or a file, can be granted with a given capability. Each capability is independent from each other.
For instance, a user process with just CAP_NET_BIND_SERVICE capability can open ports bellow 1024, however it can not kill any process or use chroot.
All linux kernel capabilities list can be found on man pages as well as code.
Instead of checking effective UID of user, modern kernels checks for capabilities, so they allow the privileged operation if capability bit is set in the effective set.
structfile{union{structllist_nodefu_llist;structrcu_headfu_rcuhead;}f_u;structpathf_path;structinode*f_inode;/* cached value */conststructfile_operations*f_op;/* * Protects f_ep_links, f_flags. * Must not be taken from IRQ context. */spinlock_tf_lock;atomic_long_tf_count;unsignedintf_flags;fmode_tf_mode;structmutexf_pos_lock;loff_tf_pos;structfown_structf_owner;conststructcred*f_cred;structfile_ra_statef_ra;u64f_version;#ifdef CONFIG_SECURITYvoid*f_security;#endif/* needed for tty driver, and maybe others */void*private_data;#ifdef CONFIG_EPOLL/* Used by fs/eventpoll.c to link all the hooks to this file */structlist_headf_ep_links;structlist_headf_tfile_llink;#endif /* #ifdef CONFIG_EPOLL */structaddress_space*f_mapping;}__attribute__((aligned(4)));/* lest something weird decides that 2 is OK */
This way, we can, for example ping some host on the internet using CAP_NET_RAW capability.
Following is an example of setting a capability in command line interface.